詳しい使い方
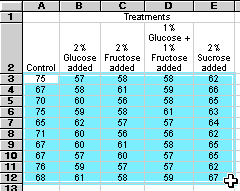
(1) あらかじめ、処理したいデータを含むセルの範囲を選択して下さい。
※ ここで数値を含むセルを選んでいないと、後でダイアログが表示されるので、そこで選んで下さい。
 |
|---|
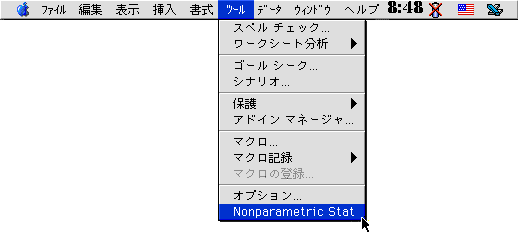
(2) メニューバーの "ツール" をプルダウンし、下の方にある "Nonparametric Stat" を選んで下さい。
 |
|---|
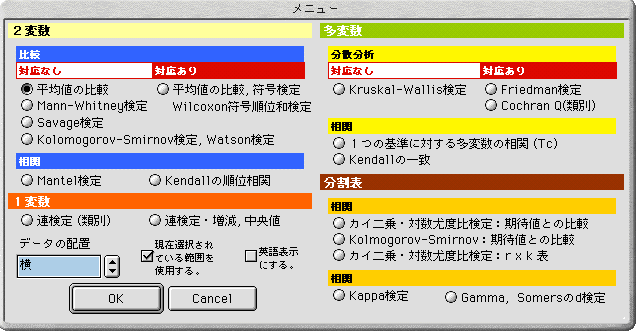
(3) 下図の様な、ダイアログが表示されます。
 |
|---|
| 現在選択されているセル範囲を使用する場合 |
|---|
2変数
お好みの統計を選択して、"OK" をクリックして下さい。
この際、データの配置は以下のように自動的に認識されます。
- 複数の領域が選択されている場合 (コマンドキーを押しながら選択すると複数の領域が指定できます)
例)A1:C3, D1:F3:それぞれの領域を別々の群として扱う
※よって、Mantel検定などで2つの変数(e.g.距離・遺伝的類似度)が同様の配置で、別表にまとめられている場合に便利。 - 1つの領域が選択されていている場合
(a) 2つの行からなる場合:1つの行を同一の群として扱う
(b) 2つの例からなる場合:1つの列を同一の群として扱う
多変数・分割表(r x k)
(a) お好みの統計を選択して下さい。
(b) 右端にある『データの配置』も
縦 (vertical)
横 (horizontal)
分離 (separate)
のいずれかを選んで下さい。
※データの配置の意味は、『現在選択されているセル範囲を使用しない場合』のダイアログの説明を参照して下さい。
(c) "OK"をクリックして下さい。
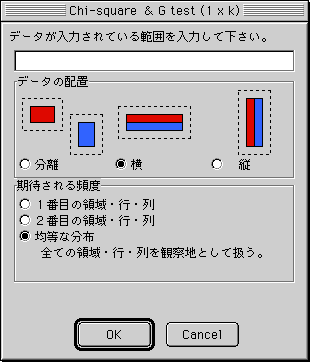
分割表 (1 x k):カイ二乗検定・対数尤度比検定
(a) メニューで選択した後、右図のようなダイアログが現れるます。上部のエディットボックスには、あらかじめ選択されているセル範囲が入力されています。
(b) データの配置(分離・横・縦)を選択して下さい。
※この際データは、頻度を意味します。
(c) "期待される頻度"がどのように入力されているか、指定して下さい。
1番目の領域・行・列:1番目の領域・行・列に期待値、2番目の領域・行・列に観察地が入力されているとして処理します。
2番目の領域・行・列:2番目の領域・行・列に期待値、1番目の領域・行・列に観察地が入力されているとして処理します。
均等な分布:帰無仮説が"全ての頻度が均一である"としてとして期待値を自動的に割り振ります。入力さているデータは全て観察値として処理します。
※期待値は、相対的なもので構いません。自動的に、期待値の合計で割り、観察値の合計をかけます。
(d) "OK" をクリックして下さい。
![]() 入力されたデータが 1 x 2 の表だった場合、二項検定も行います。
入力されたデータが 1 x 2 の表だった場合、二項検定も行います。
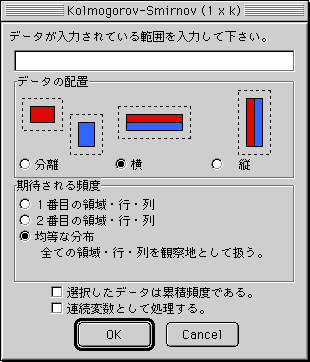
分割表 (1 x k):Kolmogorov-Smirnov検定
(a-c) 上の"カイ二乗検定・対数尤度比検定"の (a-c) と同じです。
![]() 入力された頻度は、その項目によって左から右・上から下にソートされていることを前提にしています。
入力された頻度は、その項目によって左から右・上から下にソートされていることを前提にしています。
(d) 入力さている頻度が、左から右・上から下に累積されている場合、"選択した頻度は累積頻度である" をチェックして下さい。
(e) 入力された頻度が、連続変数に基づいて求められた場合に、"連続変数として処理する" をチェックして下さい。
入力された頻度が、離散的な変数や、まとめられた連続変数に基づいて求められた場合には、この項目はチェックしないで下さい。
(f) "OK" をクリックして下さい。
| 現在選択されているセル範囲を使用しない場合 |
|---|
現在選ばれているセルではないデータを処理したい場合には、右端にある『現在選択されている範囲を使用する』のチェックボックスをオフにして下さい。
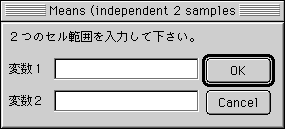
2変数
(a) 左図のようなダイアログが現れるので、データが入力されているセルの範囲を指定して下さい。
※セルを直接ドラッグすることで選択できます。(b) "OK" をクリックして下さい。
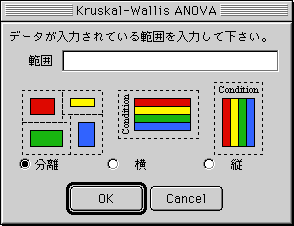
対応が無い多変数:Kruskal-Wallis検定
(a) 右図のようなダイアログが現れるので、データが入力されているセルの範囲を指定して下さい。
※セルを直接ドラッグすることで選択できます。(b) データの配置(分離・横・縦)を選択して下さい。
分離:コマンドキーを押しながらセル範囲選択すると複数の領域を選択することが出来ます。
この場合、それぞれの領域が異なる条件で処理されデータ群として扱います。
例) A1:B4, C2:F5, A6:C9 ⓠ3つの条件で処理されたデータ
横:行毎に異なる条件で処理された群として扱います。
例) A1:B4, C2:F5, A6:C9 ⓠ9つの条件(行1, 2, 3, 4, 5, 6, 7, 8, 9) で処理されたデータ
縦:列毎に異なる条件で処理された群として扱います。
例) A1:B4, C2:F5, A6:C9 ⓠ6つの条件(列 A, B, C, D, E, F) で処理されたデータ
(c) "OK" をクリックして下さい。
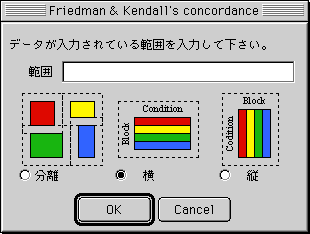
対応のある多変数:Friedman検定 & Kendallの一致・1つの基準に対する多変数の相関 (Tc)
分割表 (r x k)
(a) 左図のようなダイアログが現れるので、データが入力されているセルの範囲を指定して下さい。
※ セルを直接ドラッグすることで選択できます。(b) データの配置(分離・横・縦)を選択して下さい。
分離:コマンドキーを押しながらセル範囲選択すると複数の領域を選択することが出来ます。
この場合、それぞれのブロック・領域を1つの群(条件ではない!)として扱います。
例) A1:B4, C2:D5, Y10:Z14 ⓠ3つの群を8つの条件で処理したデータ
横:行毎に異なるブロック・群(条件ではない!)として扱います。
例) A1:E6ⓠ6つの群 (行1, 2, 3, 4, 5, 6)を、5つの条件で処理したデータ
A1:B6,D1:E6ⓠ6つの群 (行1, 2, 3, 4, 5, 6)を、4つの条件で処理したデータ
縦:列毎に異なるブロック・群(条件ではない!)として扱います。
例) A1:E6ⓠ5つの群 (列 A, B, C, D, E)を、6つの条件で処理したデータ
A1:B6,D1:E6ⓠ4つの群 (列 A, B, D, E)を、6つの条件で処理したデータ
※順位は、ブロックの内部で独立につけられます。
![]() 1つの基準に対する多変数の相関(Tc)では、全てのブロックが1つの基準によってソートされていることを前提としてます。
1つの基準に対する多変数の相関(Tc)では、全てのブロックが1つの基準によってソートされていることを前提としてます。
(c) "OK" をクリックして下さい。
![]() "カイ二乗・対数尤度比検定 (rxk)" で 2 x 2 の表だった場合、Fisherの正確確率検定法も行います。
"カイ二乗・対数尤度比検定 (rxk)" で 2 x 2 の表だった場合、Fisherの正確確率検定法も行います。
(4) サンプル数(N)・統計量・可能な組み合わせ数(All permutations)や、一部の検定では総計量を既知の分布(正規分布, χ2分布, F分布)に近似させて算出した棄却率(p)が、ダイアログに表示されます。
(5) 比較的可能な組み合わせ数が少ない場合が多い統計(2変数:平均値の比較,Mann-Whitney検定)では、全ての組み合わせを計算するか、否かを訊ねられます。
この際、組み合わせ数が10,000以上であったら、計算に時間がかなりかかるので『いいえ』を選択して下さい。
(6) 可能な組み合わせ数が非常に多い統計や、(5)で『いいえ』を選択した場合、無作為に抽出する組み合わせ数をいくつにするか訊ねるダイアログが現れます。お好みの回数を入力して、『OK』を選択して下さい。
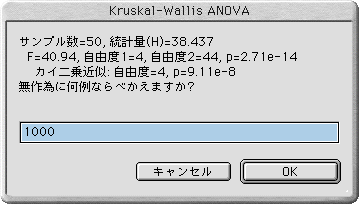
※ ここで "キャンセル" クリックしても、近似によって算出した棄却率をテキストボックスに表示します。
(7) 計算が開始され、画面下のステータスバーに、途中経過(観察値と同じかより極端なケース/ならべかえ回数)が表示されます。
(8) 計算が終了すると、結果がテキストボックスとして選択したデータの周辺に表示されます。

※ 全般的な注意
※ Mantel検定は片側検定です。